Solidify: Using GitHub Actions Securely
Today I got to deliver my session “Using GitHub Actions Securely” at the Solidify show, hosted by our friends at Solidify. A nice virtual community session during lunch in my time zone (CEST) with people joining in, even from Kuala Lumpur!
I got a couple of questions during the session that I wanted to dive deeper into and address them here, as well as sharing the slides and the recording of it.

The session has been recorded and you can re-watch it on YouTube or here:
Slide deck
I you want to look up some things from the slides or visit one of the many links in there, you can look at the slide deck here.
Question: Can you prevent a reviewer to approve their own changes on a Pull Request?
Full question: “I would like to enforce that at least two people are involved with every change made to a protected branch. GitHub by default allows a reviewer to approve their own changes to a PR, which makes it possible to use any open PR to merge changes possibly for making an attack on the production environment. Do you have any guidance how to avoid such a scenario?”
You can use branch policies to set up rules that need to be met before a Pull Request be merged:
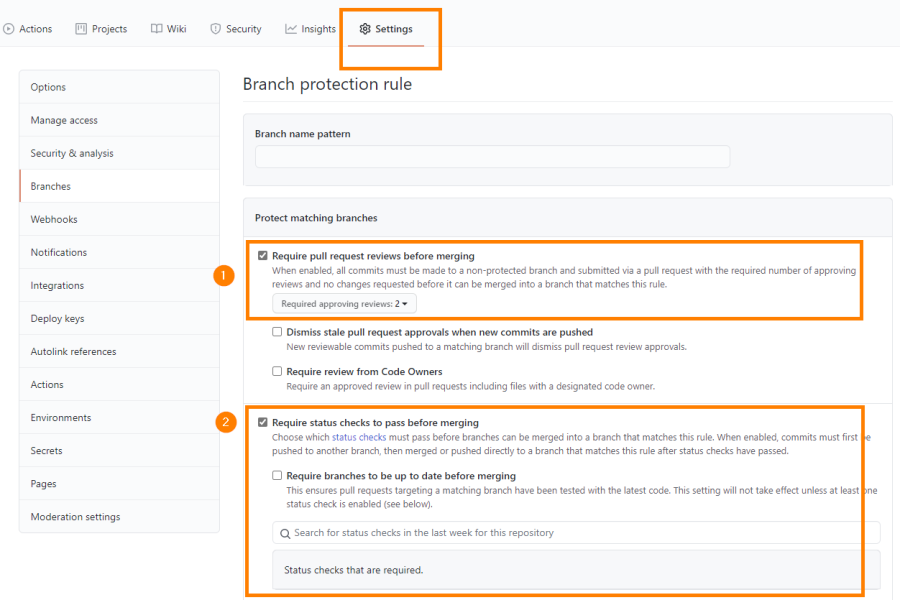
With the default setup people with higher access levels can still merge the pull request:
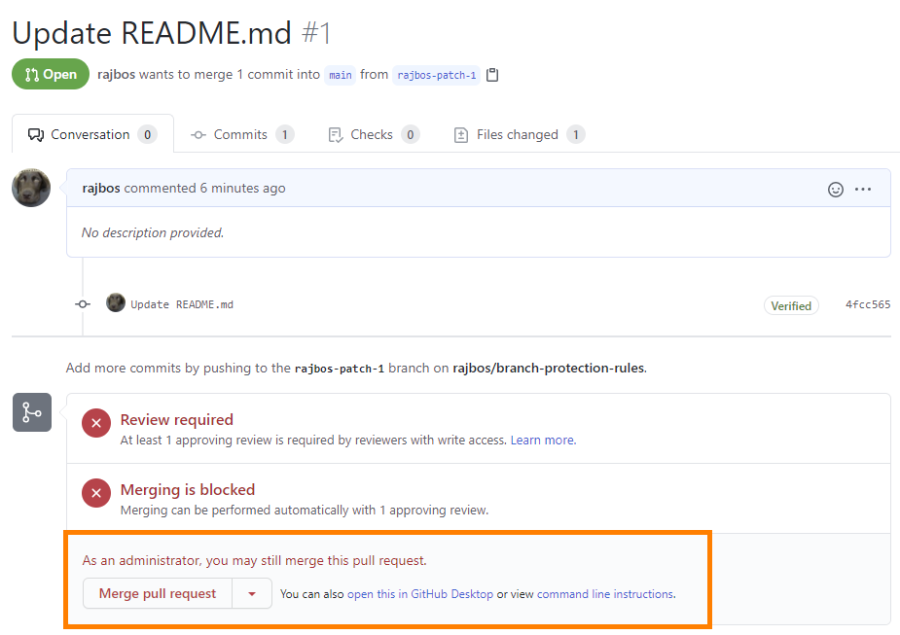 I see two options to still enforce that someone else needs to review the PR:
I see two options to still enforce that someone else needs to review the PR:
- Add a minimum of 2 reviewers: then the PR author always needs to review the PR their self as well as an extra reviewer.
- Add a check that verifies that there was an extra reviewer, next to the PR author. You can create that check with a workflow that posts back the status after a reviewer has approved the PR.
Question: Would you recommend actions always to executed in containers?
Yes! As much as you can: that gives you a nice extra security boundary for the stuff you actions are doing: instead of running those processes on the runner process itself, it will run them in a container. This is also a good way to prevent stuff from being installed on the runner machine: for example, you can use the OpenJDK image to build your JAVA project, without installing JAVA on the host machine. You get an extra security layer on top of it as well. Breaking out of a container can probably still be done, but is a bit harder to do. This also helps with anything else remaining on the machine, like files on disk, stuff in the environment variables. You can read more in the ephemeral runners section below.
Question: Is it possible to run the GH Actions in Self Managed Kubernetes cluster in Cloud?
Yes there is! There are multiple community projects available to run the runners in a scalable, self hosted way. The default is installing the agent your self on a VM of your choosing. If you want to add autoscaling into the mix, and get ephemeral runners as an extra benefit, you can look into this list of curated community solutions for hosting them on your own infrastructure, for example Kubernetes. I’ve used one option myself that I’ll add the experiences below.
Lets first explain ephemeral runners:
An ephemeral runner is only spun up for a specific workflow run, and only exists for the duration of the run. Afterwards it is deleted and cannot be used anymore. This is of course an ideal setup to use with Kubernetes: when you need capacity (a workflow is scheduled): spin up a container with the workflow runner inside of it, register it with GitHub, and execute the workflow. Doing this with a Virtual Machine is a lot more time consuming and difficult to do, even with the cloud. If you really have the need, you could use it that way.
Using an ephemeral runner also means that there is no option for state (files stored on disk, environment variables) to linger on the environment that could potentially be picked up by another workflow that executes on the same runner.
Actions runner controller
The solution I’ve been testing things out is the Actions runner controller. This one is spun up as a controller on Kubernetes (I used AKS for it) that periodically checks with the GitHub API if there are jobs waiting in the queue. If so, it will spin up a new container with the runner inside of it, register it with GitHub and let it do the work for you. After the job is done, the container will be removed and deleted. The container will execute the workflow itself, or leverage Docker in docker to create a container if your actions need them.
This works really nicely: I’ve hammered it with 6 workflows in the same repository that spun up over 20 jobs at the same time: scaling kicked in and created multiple runners for me. After the completion there is a cool off period, where the runners are being removed completely after 10 minutes (the default setting).
