DevOps Maturity Levels
I was thinking about the teams I’ve been helping out in my professional work life and suddenly noticed that there seem to be different stages that each team goes through in an effort to improve something in their day-to-day work. Usually I start at a new assignment with a specific question and together we evolve my assignment from there.
The entry point often is something specific, like for example:
- Migrate our on premise source control to something in the cloud (usually much newer)
- Quality assessments of the code base
- Way of working to get changes into production
After the initial question is handled (or planned to be handled), I often start helping the teams with additional steps they can include to improve certain aspects of their way of working and we go from there.
Since my expertise is DevOps, all these things are around those topics. I’ve done a lot of things around the DevOps cycle, from explaining Git as a way to version your code to monitoring in production and deployment into a cloud environment. Note that these items are mostly based on using technology to improve things. The world of people and culture in an organization is for another time 😄.
DevOps - States of enlightenment
Looking back at my assignments, I found different states where the teams where in their DevOps way of working and from that you can find the next thing that would probably help to improve their environment. With environment I mean everything they do to keep the application running in production. Of course, some teams already have (part of) these topics handled, so you can check other states as well to find possible improvements.
I’ve tried to set these in a logical order in the image below and will (try to) create a blog post for each stage to describe what this means and ways to implement this in your setup. You can always dive deeper into a specific item no matter where your team is in the improvement process or skip things and come back later. In my mind, this is an order that makes sense to me:
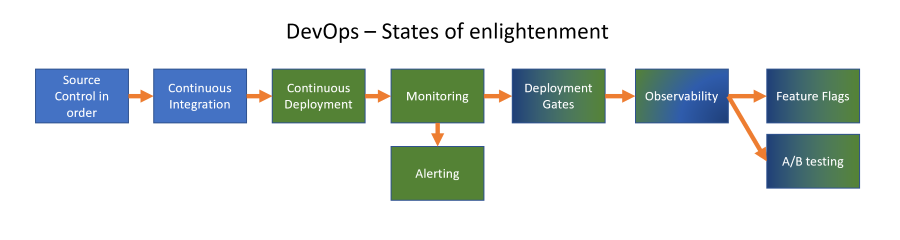
I’ve color coded the states indicating their main point of view and if this is Developer driven (blue) or Operations driven (green), although this is not always as clear cut of course.
Dev - Source control in order
From a developer perspective you need to have your source control in order. I still come across code that is not version controlled at all 🙀, sometimes it just sits on a user machine, a share or even worse: on the shared server used for CI/CD (continuous integration and deployment)! Link 👉 DevOps - Source control in order.
Dev - CI (continuous integration) pipelines
From a developer driven wish they usually start implementing something of a continuous pipeline, that at least builds the code on a different machine then the developer who wrote that code. This state will be split up into different maturity levels since there are a lot of different improvements to be made. Link 👉 DevOps - Continuous Integration.
Ops - CD (continuous deployment / delivery) pipelines
Often times the people who are deploying the application to an environment have the need to automate these actions into a repeatable process that can be executed without manual interactions. I’ve still seen teams that where orchestrating this process with six designated team members, each having to wait for someone else was done to start the next step in the deployment by running their own batch file (non versioned of course!) with custom settings for that environment. This state also can be split up into multiple maturity levels. Link 👉 DevOps - Continuous Deployment
DevOps - Pre and post deployment gates with actual checks
This is the first common scenario where both dev and ops have a stake to get things done: operations usually has an interest in checking if things are still working after a deployment and this often is the last step for the developers when they thing their work is complete.
Ops - Beginning with monitoring
Heavily ops driven of course, although (finally) devs are more and more looking at the actual running application to see how things are going. To get more insights, monitoring is an important topic to handle. When devs start to tackle this, they often take a different starting point then someone with an operations background.
Ops - Alerting
When monitoring is setup, it would really help a lot if you also get alerts from your monitoring setup. Often you start here and you get too many alerts. Getting this right is hard, yet very important. From alerting you can also start with a good recovery mechanism, like adding playbooks/runbooks to start a recovery procedure (this could even be scaling things up/out).
Ops - Observability
Often triggered by something from monitoring (hence ops), the need arises to have actual insights into what the application is actually doing. Developers usually have the insight in where you can add additional logging in the application to get that information out, hence the color gradient in the image: it starts with ops (often) and then becomes a joint effort to get the information out.
DevOps - Feature flags
After having more information about the application through basic logging and observability, you can get on the way with proper feature flags: toggling a flag to enable/disable something in the application/environment to for example enable new features, or disable a recommendation engine on black Friday to have a more reliable application. This is often a joint effort between dev and ops minded people.
DevOps - Rapid A/B testing with user cohorts
When you have feature flags in your system, often you then have another light bulb go off: you can start using these to test in production! Why not give certain users a label like ‘internal’, ‘beta-tester’, ‘customer’ and have only those groups test new features? This enables canary releases (a subset of users get the new feature) or even actual A/B testing to see which application flow gets more customers to buy a product.
