GDBC DevOps on the Leaderboard
Global DevOps Bootcamp
On the 16th of June 2018, Xpirit and Solidify organized a global event around the topic of DevOps and improving your release cadence. It is an ‘out of the box’ event with a lot of self organization where people around the global gathered on their free Saturdays to learn something new about DevOps.
People interested in hosting a local venue went to the site https://globaldevopsbootcamp.com/ and started from there. Anybody, anywhere could host an event. Eventually, 76 venues registered with 8.000 participants!
The teams from Xpirit and Solidify provided completely configured VSTS accounts, with challenges, webhooks, users and a filled git repository:
Showing how we worked
We got several questions during the event how we organized the leaderboard application and some participants where astonished we used the same tools for this as they had been working on today! That’s why I wanted to share some of the stuff we did and what happened during the day!
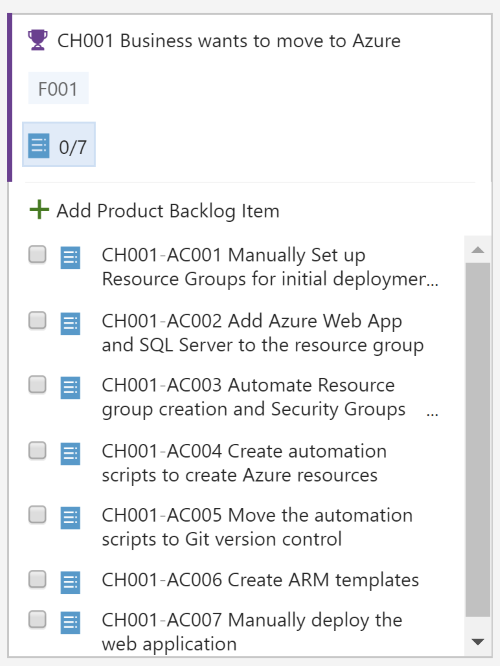
Getting points for work items
Every time a workitem’s state changed, a preconfigured webhook was triggered. When the team moved a work item to state ‘done’, they would get points for that work item. Points were depending on the amount of work necessary to complete the challenge. The team could also request help, by adding a tag to the work item. Doing so would cost them half of the points for that work item, but also provided a link to a zipfile containing step by step instructions.
Leaderboard application
To organize all this, Peter Groenewegen and Geert van de Cruijsen created a leaderboard application for last years event. You can find the source for it on GitHub: github.com/xpiritbv
We build on that for this years version, where Peter has added the webhook callback so VSTS could tell us when a workitem changed.
Off course, this .NET core application is hosted in Azure on an App Service instance backed by an Azure SQL Database. The code is on GitHub and we created a build and release pipeline in VSTS:
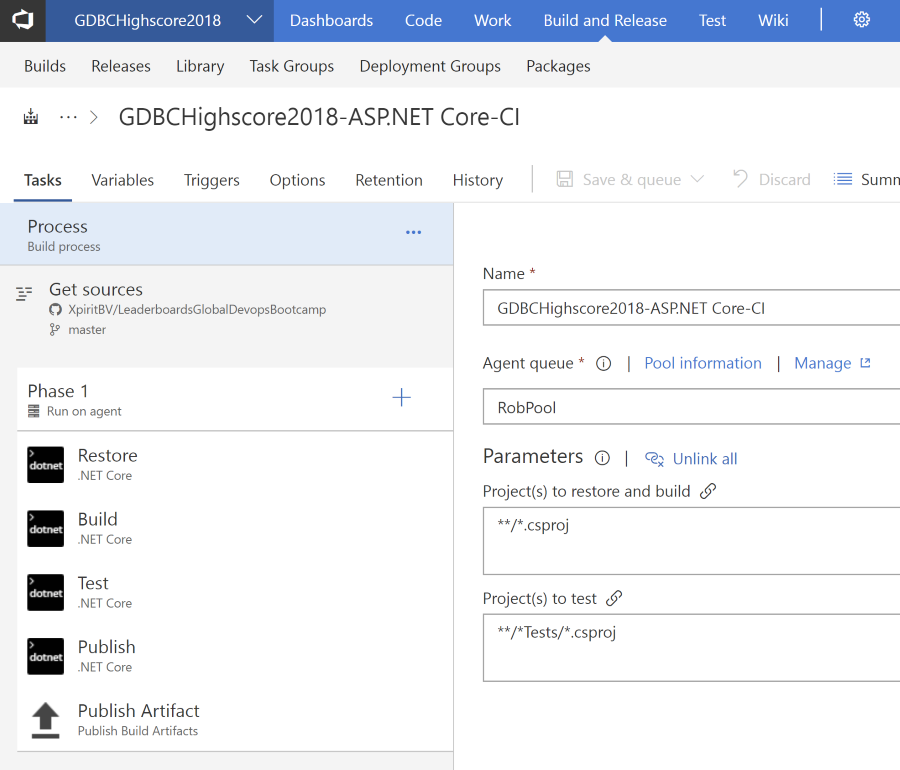
This build would trigger when a pull request got merged into master and after successfully running all unit tests would trigger a release.
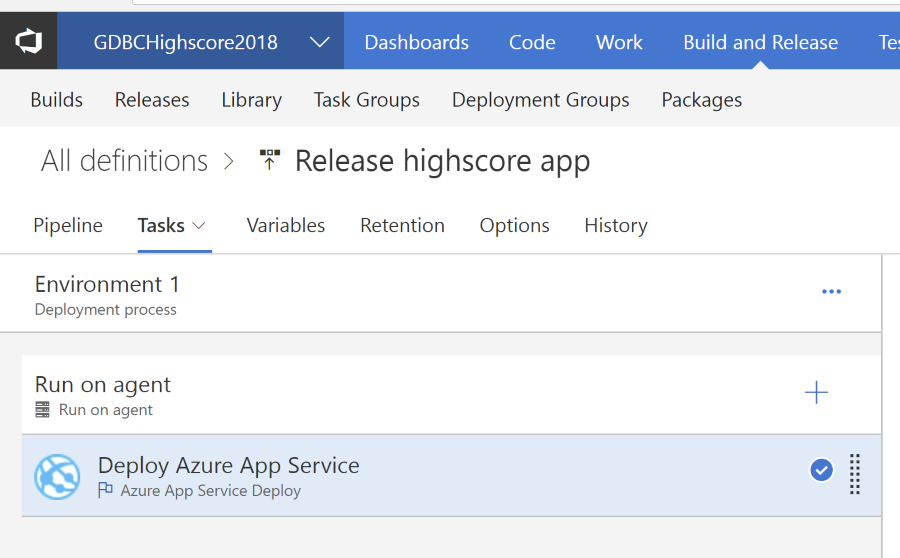
DevOps for the leaderboard application
To check the application during the event, we created a dashboard to monitor the performance of the application and the database.
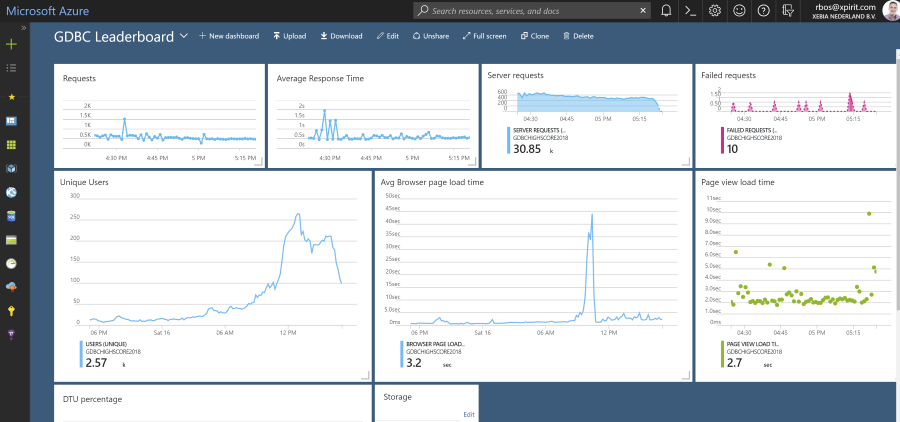
During the event
The event started everywhere at 10:00 AM local time, so New Zealand and Australia got to be the first to use the application. We were a sleep during most of that timeframe, but we checked during the start to see if there where no errors. Luckily, that wasn’t the case!
 Checking issues together with Geert, image by Jesse Houwing.
Checking issues together with Geert, image by Jesse Houwing.
EMEA region starting with the challenges
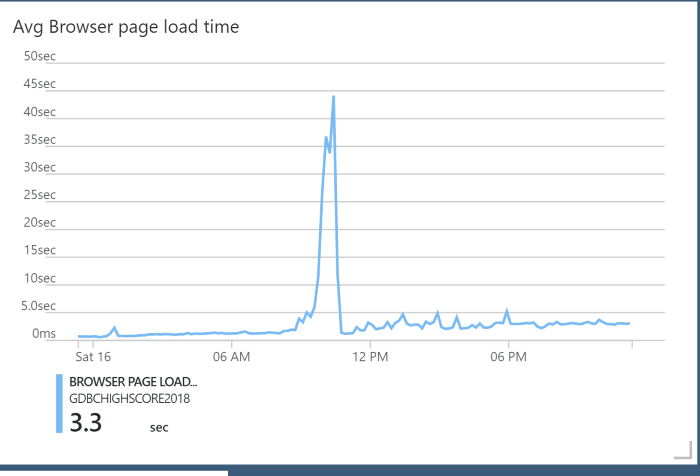
When we started in Hilversum, The Netherlands, 10:00 AM CET, we noticed the average page load time climbing up and up. Apparently, a lot of venues in the EMEA region where using the leaderboard and where updating the workitems, causing some load on the webhook as well!
We quickly scaled the App Service Plan and the Azure SQL Database to fix the page loads. This was important, because the webhooks where also on the same endpoint. When a webhook fails a couple of times, it will be disabled! That would mean teams not getting new points for the challenges they would complete!
Thanks to the power of Azure and our team being enabled to fix things while running, we mitigated the issue.
Failing webhooks
A couple of hours later, someone spotted errors in Application Insights for the calls into the webhook. Checking the callstacks and exception messages, we found the culprit. We made sure we checked the workitems coming in to find their correct tags so we could find the points they where gathering, but we didn’t anticipated our participants creating their own workitems and tasks to distribute the work between them! This meant the webhook was being called with workitems that didn’t have any tags! So: a simple edge case we missed in our unit tests!
A commit, push, pull request, review and merge later, the CI/CD pipeline we created kicked in and the application was pushed to production! Just like the teams where learning to use today!
Other issues
Somehow, some teams managed to trigger the webhook in such a way that we got a duplicate record in the database. We found out about this, again through Application Insights, and fixed the issue quickly. How they managed to trigger this, is something we will look into before using the application again.
Can you spot where we scaled the database?
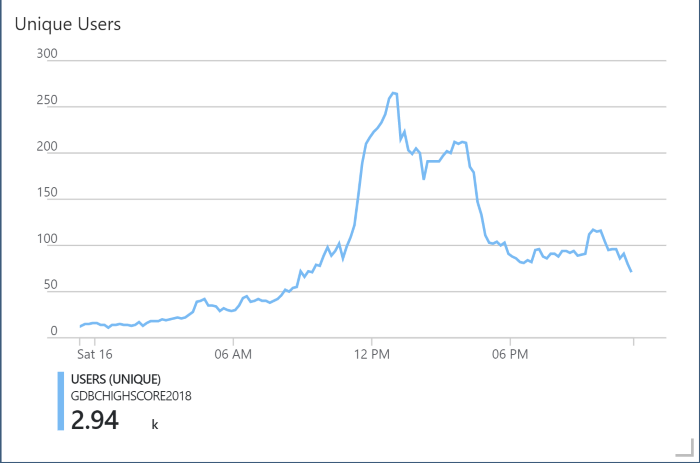
Usage throughout the day
There was a noticeable bump for the period EMEA region was live:
Closing
All in all, I think we managed to keep the leaderboard and the webhooks in the air without our users noticing much of these issues. Great to see what a team can do when the have control over their entire pipeline, even into production!
That’s why we need to keep repeating the message: empower your teams!
